
In my previous article, I described the most important factors for on and off-target execution. We will now take a closer look at one of the most important factors for such differences, namely the compiler.
Most C and C++ developers are familiar with the term undefined behaviour. Here, the standards allow the compiler some freedom in terms of interpretation. But the fact that this can quickly lead to very subtle deviations in off-target behaviour is not as well known.
There are a total of three different categories of freedoms, which are granted by the C++ standard compliant compilers. First of all, we will get a brief overview, based on the definitions from the current C++17 standard. By the way, the C18 standard defines the terms in the same way.
- unspecified-behaviour: behaviour, for a well-formed program construct and correct data, that depends on the implementation
- implementation-defined behaviour: behaviour, for a well-formed program construct and correct data, that depends on the implementation and which is documented at each implementation
- undefined behaviour: behaviour for which this International Standard imposes no requirements
Unspecified Behaviour: surprisingly mundane
Unspecified behaviour refers to the correct programmes that use language resources in an unspecified manner. In this case, the compiler can decide on the behaviour to be used. Unlike undefined behaviour however, the possible behaviours are transparent and understandable.
Surprisingly, one of the core aspects of the language is undefined, namely the order of execution of expressions.
foo(fun1(), fun2());
Here, one function foo is called up with two parameters. Each parameter is a return value of two other functions.
For such printouts, the standard does not define whether fun1 or fun2 will be executed first and, as a matter of fact, different compilers use both variants here. The following short example illustrates the order of the evaluation.
#include <iostream>
int fun1() { printf("fun1() \n"); return 0; }
int fun2() { printf("fun2() \n"); return 0; }
void foo(int x, int y) { printf("foo() \n"); }
int main() {
foo(fun1(), fun2());
}
The output on a typical desktop compiler (an x86-64 with gcc 9.2) produces the following result:
fun2()
fun1()
foo()
The same code, with a typical embedded compiler (an arm-gcc-none-eabi 8-2018-q4) executed on an ARM Cortex-M:
fun1()
fun2()
foo()
The execution order of the embedded compiler is therefore in reverse, compared to the desktop compiler.
This example simply produces a different output. Both functions always produce 0. However, it is easy to imagine the effects that occur when fun1 and fun2 access the same data and evaluate and change it.
To the best of my knowledge, there is currently no compact list for unspecified behaviour. Fortunately, this does not apply to another category of compiler-dependent behaviour.
Implementation-defined behaviour: Portability problems
Implementation-dependent behaviour differs from unspecific behaviour in one important aspect: here, the manufacturer of the compiler must document what behaviour it uses. This means, in particular, that the behaviour for this type of compiler remains identical across different cases.
The C++ Standard itself has a list of all positions that are subject to such documentation requirements. However, with 235 different items, this list is relatively extensive.
Some of the points appear plausible right away: The alignment of datatypes must of course be dependent on the target architecture. If the hardware only supports 4-byte integers at 4-byte addresses (0x00, 0x04, 0x08, …), the compiler must take this into account. A standard definition of such characteristics across many hardware architectures, in a way that makes sense, is simply not possible. Platform independence is one of the great unique selling points of C and C++. Therefore, the best option is to define such aspects as implementation-dependent.
The other items on the list do not seem to have such a strong justification. In any case, to me, it does not seem immediately clear, why the value of ZERO should be implementation-dependent.
Example: The type of enums
The standard tells us that it is implementation-defined which integral type is used as the underlying type except that the underlying type shall not be larger than int unless the value of an enumerator cannot fit in an int or unsigned int.
If you want to see how this can cause practical bugs, see our investigation about a bug in ARM Mbed. The bug we found is caused by the changing underlying type of an enum.
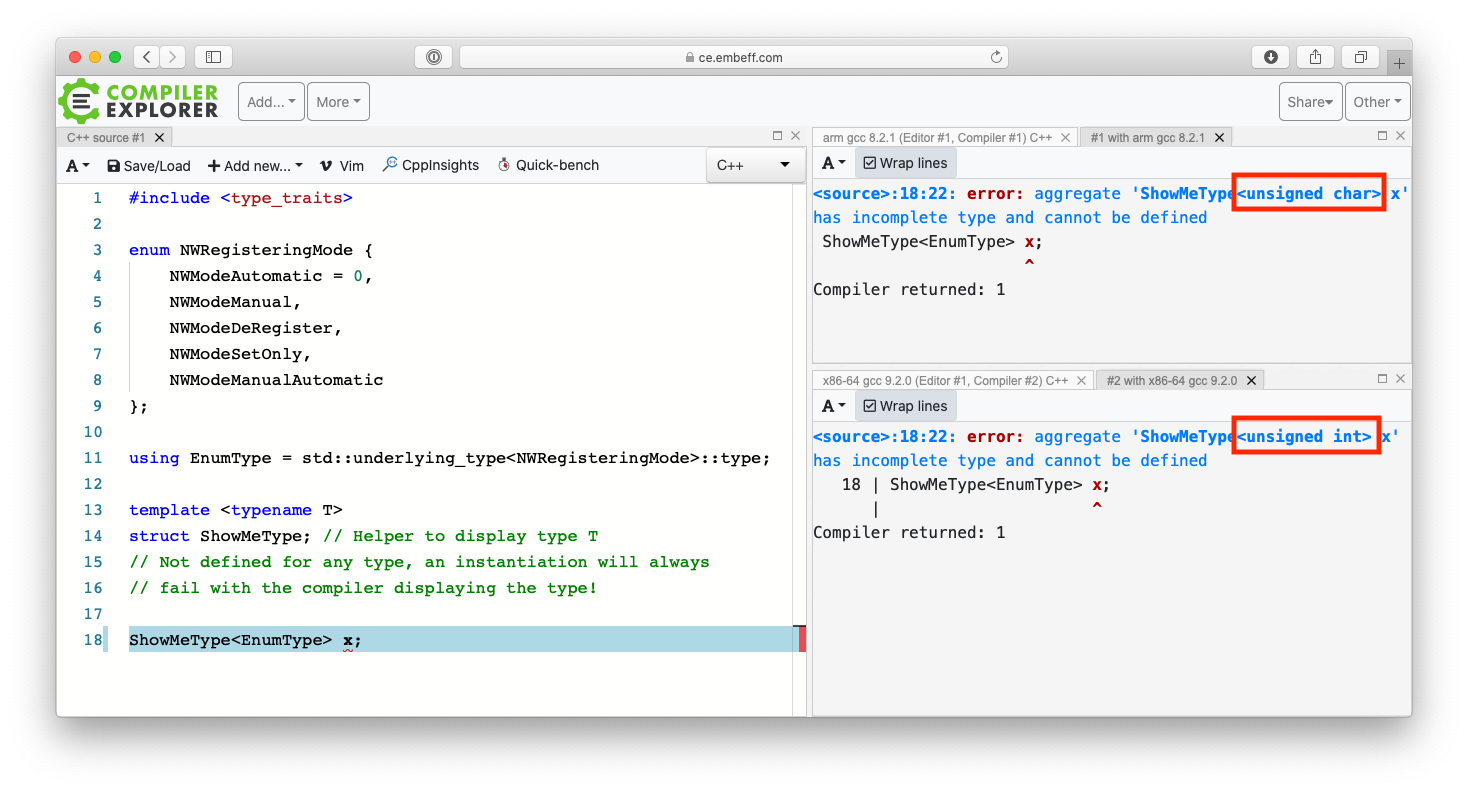
As you see in the picture, one compiler chose unsigned char, the other unsigned int for the same enum. Depending on what you are doing with the enum values (consider bit-operations); the calculations may yield different results for different underlying types.
Undefined behaviour: Odd behaviour
The following link provides a concise summary of undefined behaviour:
Renders the entire program meaningless if certain rules of the language are violated.
If you (unconsciously) violate the rules of the language, the entire program could be interpreted as nonsensical by the compiler. The following example shows the dangers that lurk in such situations.
int f(bool parameter) {
int a; // uninitialized local variable
if(parameter) { a = 42; }
return a; // Possible access on an uninitialized variable
}
Access to uninitialized variables violates the rules of the language, and is therefore undefined. What does the compiler do in this case? A glance into the assembly that is generated is very enlightening here.
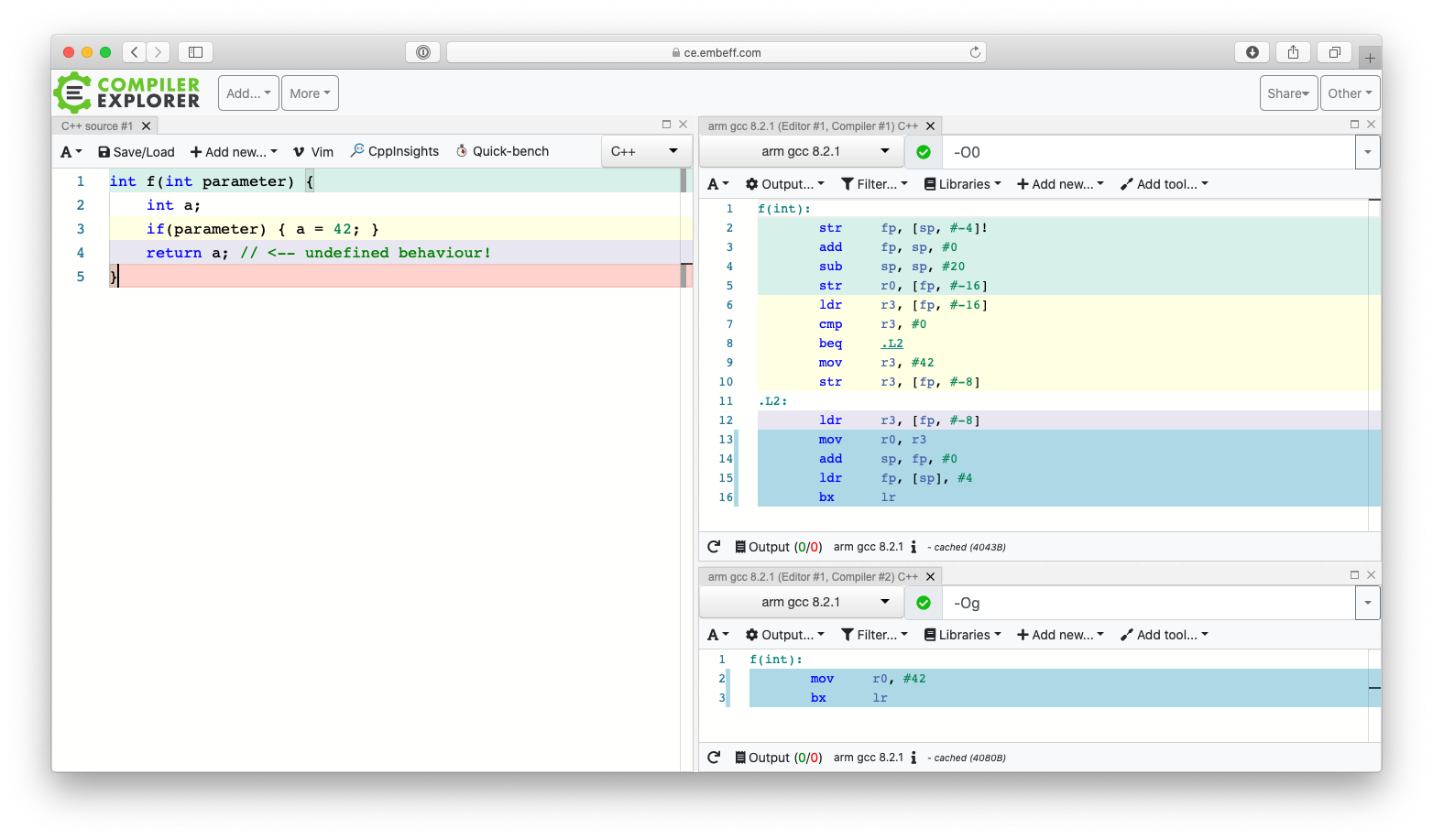
- With optimization switched off (-O0), the parameter is checked for inequality with 0, and only then does the code return 42. Otherwise, the value of the local variable “a” is returned. Memory has been reserved on the stack for this purpose, but it has not been initialized. Therefore the return value depends on the contents previously stored in this RAM location.
- If optimization is switched on (-Og), the parameter value is not evaluated, and the code always returns 42.
So, the code exhibits a completely different behaviour, depending on the optimization level. Since the variable access is undefined behaviour, this interpretation is permissible.
Effects on embedded development
Unspecified, implementation-dependent and undefined behaviour are important aspects of C and C++. Compilers are given degrees of freedom and allowed room for interpretation, according to the respective standard.
It is therefore always necessary to test code with the compiler that is used for the final product, using the same settings. This generally also requires on-target execution on the actual target system. Otherwise, you could encounter hidden risks and a security that is purely perceived.